Shelf Life
🗓 posted Jan 31, 2025 by Josh Erb🔢 1080 words
🏷 #web #development
Earlier this week I soft launched a "bookshelf" on this website. This first iteration isn't fully featured, but it builds on some of the workflows I started to think about in Dropping the Ocean, and I want to document what it took to make this initial version.
Initial Sketches
I've been noodling on the idea of owning my own reading data for a while now. I first noted down the idea for this project way back in 2020.
My initial plans were fairly ambitious. They included building out new APIs, a dedicated endpoint, and a private front end I could access on my phone to make updates.



When I thought about it some more, I became less convinced that this was the right direction. I wanted a robust workflow, but I started to shy away from baking it from scratch because I didn't want the cost & burden of maintaining a new backend & a front end app. Especially as this work was marinating, I realized that my current tracker app (Oku) exposed high-level data for my lists (currently reading, read, to read) as distinct RSS feeds.
I started to think about how I could do all of this with with an elaborate system of GitHub issues that triggered actions.[1]
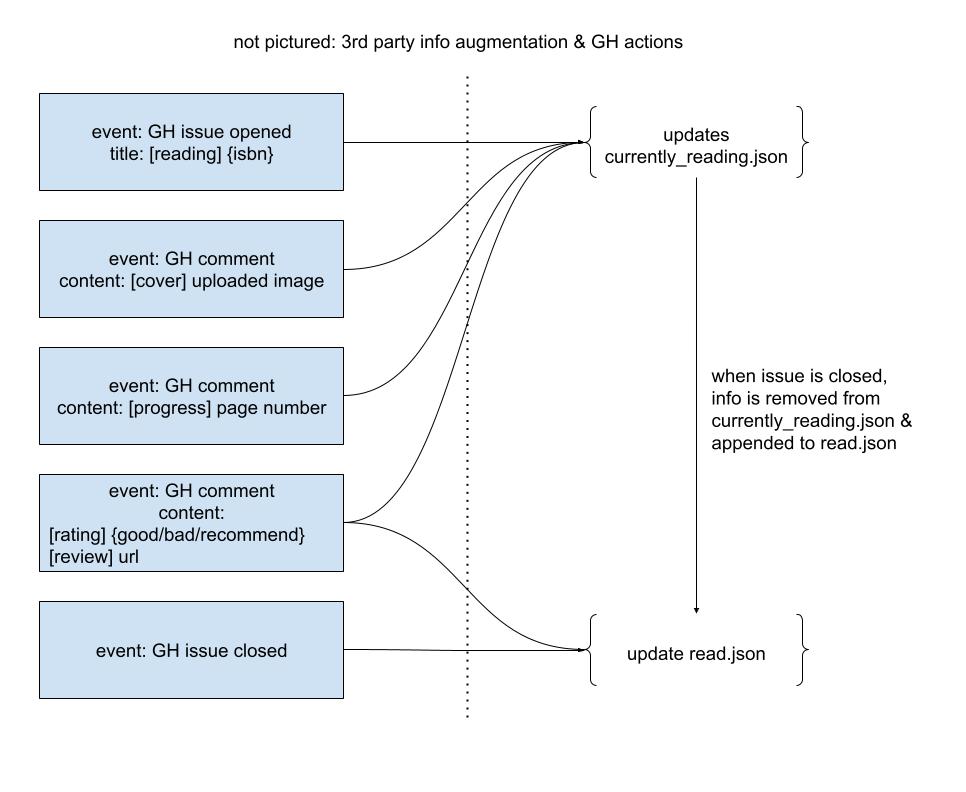
This still didn't feel quite right for my current needs, though. I made the above diagram and then sat on my hands a bit more. In October 2024, I did a bit of prototyping & playing around with styling in a dedicated branch. I liked the results, but I didn't feel confident enough in the data piece to roll with it.
It wasn't until more recently, as I was tweaking how I display the books I am currently reading on the site's landing page[2] that I realized I could get a bare bones setup of the page thrown together using a similar approach.[3]
I made a note and decided to circle back when I had more time.
Setbacks
When I finally sat down to build this page this week, I wanted to stay close to the playful style I had experimented with when I was prototyping last October. I reused some of the CSS and even deployed the page looking like this:
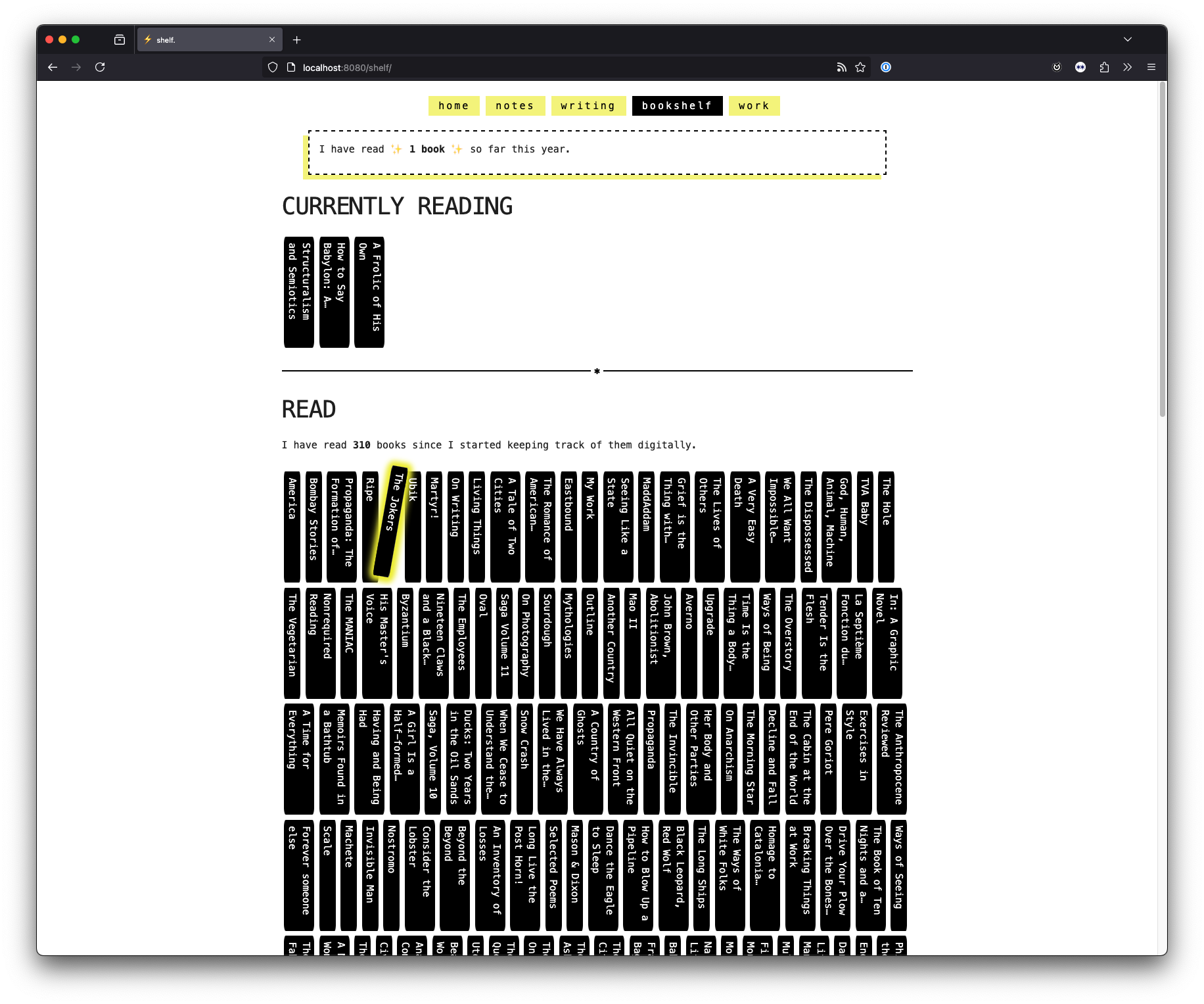
However, it didn't take me long to realize that my preferred styling was broken on Safari. Turns out Safari (Desktop & iOS) does not know how to handle the use of line-clamping / text truncating logic when it is combined with vertical text.

I waffled on whether to remove the line-clamping & text truncation, but that ended up making any book with a longer title look like a fat tome and the effect felt poorer for it.
In the end, I dropped the nod to a real bookshelf and went with basic HTML table.
Technical details
So here's the approach I've finally landed on, which I'll try to provide as an overview without doing too much rewriting of what I mentioned in Dropping the Ocean.
The secret sauce is really how eleventy does global data files. I am able to store my currently reading & have read data as static JSON files in my site's repo. Using Nunjucks iteration, I can loop over the items from these files & bake their attributes directly into the HTML that is generated at build time.
In order to ensure data is auto-updated when I add or remove books from either of these lists in Oku, I have a GitHub scheduled action which runs 6 times a day. This action fetches the content returned by an RSS feed & parses it from XML into JSON. Once it has successfully retrieved & parsed these data, it compares them to the data that are at the latest HEAD of my repo's main branch. If the data do not match, the action overrides the existing file & commits the changes.[4]
After this commit is made, my build & deploy workflow is triggered. Roughly a minute later, the live page has been updated with the latest data.
Results
You can see the final results of this bit of work over on the bookshelf. Here's a quick screenshot for posterity:
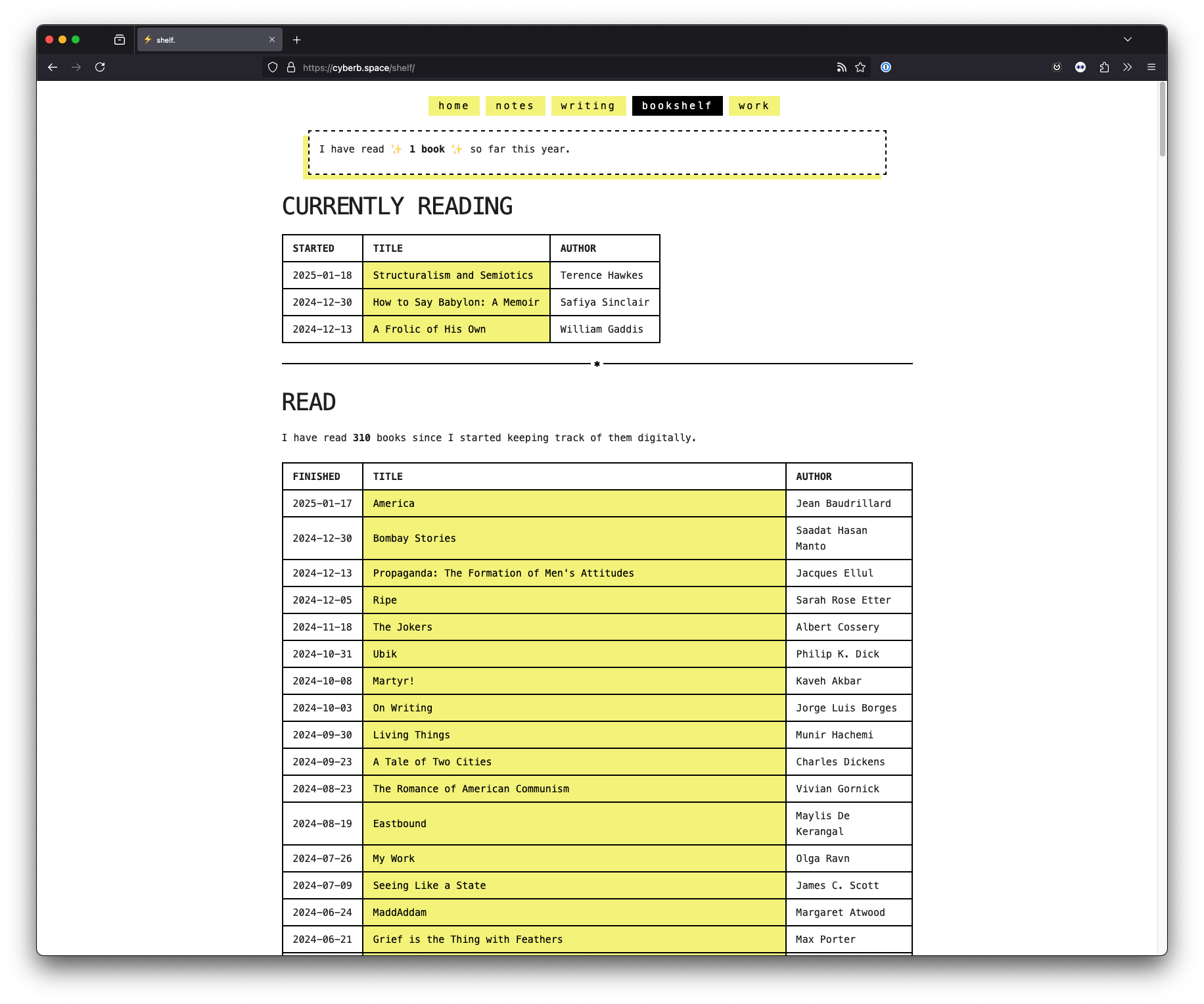
I have quibbles, of course:
- Book subtitles are included in the titles, which screws with formatting on mobile.
- There is no connection to any ISBN, publication, reading journey, or reviews in the data.
- The initial nod to skeuomorphism in my original design was fun. A simple table feels a bit bland.
Most of these can be fixed with some work on improving data quality and a new plan of attack for the CSS. For the sake of getting something done & not letting this languish in a draft branch, though, I pushed these concerns aside.
More to come
There's a yawning gap between the current state of this page and what I have in mind. While this initial workflow & design is fine for now, I plan to circle back and tackle a few more things in the future: having each book link to a dedicated review page, begin & end dates for read books, grouping read books by year — the list goes on and on.
I find that scoping out projects as these big, hulking things can be overwhelming to the point where they just sit in my notebook for years. Freeing myself to build a part of the thing, instead of the whole thing helped me make more progress on this than I have in the last 4 years combined. I approach my professional work this way, but this was one of the first time's I felt it so clearly on a little personal project.
This thought was heavily inspired by a former coworker, Katy Decorah, sharing how she built her own reading tracker (here). Honestly, she makes these things look effortless and she's a great RSS subscription.
This is discussed in greater detail in this post.
Recorded this realization for my future self here
These commits are atomic, you can see an of adding a new book to my currently reading here.
<< all notes.